Training face landmark detector
This demo helps to train your own face landmark detector. The user should provide the list of training images accompanied by their corresponding landmarks location in separated files.
Examples of datasets are available at https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/.
We suggest you to download the HELEN dataset which can be retrieved at https://ibug.doc.ic.ac.uk/download/annotations/helen.zip (Caution: The algorithm requires considerable RAM to train on this dataset).
Example of contents for images.txt file:
/data/helen/100032540_1.jpg /data/helen/100040721_1.jpg /data/helen/100040721_2.jpg ...
Example of contents for annotations.txt file:
/data/helen/100032540_1.pts /data/helen/100040721_1.pts /data/helen/100040721_2.pts ...
where a .pts file contains the position of each face landmark. Example of contents for .pts files:
version: 1
n_points: 68
{
212.716603 499.771793
230.232816 566.290071
...
}For a description of training parameters used in configFile, see the demo facemark_kazemi_train_config_demo.m.

You can also download a pre-trained model face_landmark_model.dat, see the demo facemark_kazemi_detect_img_demo. (that way you can skip training and simply load the model).
Sources:
Contents
Options
% [INPUT] path of a text file contains the list of paths to all training images imgList = fullfile(mexopencv.root(),'test','facemark','helen','images.lst'); assert(exist(imgList, 'file') == 2, 'missing images list file'); % [INPUT] path of a text file contains the list of paths to all annotations files ptsList = fullfile(mexopencv.root(),'test','facemark','helen','annotations.lst'); assert(exist(ptsList, 'file') == 2, 'missing annotations list file'); % [INPUT] path to configuration xml file containing parameters for training % https://github.com/opencv/opencv_contrib/raw/3.4.0/modules/face/samples/sample_config_file.xml configFile = fullfile(mexopencv.root(),'test','facemark','config.xml'); assert(exist(configFile, 'file') == 2, 'missing train config file'); % [OUTPUT] path for saving the trained model modelFile = fullfile(tempdir(), 'model_kazemi.dat'); % [INPUT] path to the cascade xml file for the face detector xmlFace = fullfile(mexopencv.root(),'test','lbpcascade_frontalface.xml'); download_classifier_xml(xmlFace); % name of user-defined face detector function faceDetectFcn = 'myFaceDetector'; assert(exist([faceDetectFcn '.m'], 'file') == 2, 'missing face detect function'); % width/height which you want all images to get to scale the annotations. % larger images are slower to process scale = [460 460];
Data
% load names of images and annotation files disp('Loading data...') [imgFiles, ptsFiles] = cv.Facemark.loadDatasetList(imgList, ptsList); % load images and their corresponding landmarks imgs = cell(size(imgFiles)); pts = cell(size(ptsFiles)); for i=1:numel(imgFiles) imgs{i} = cv.imread(imgFiles{i}); pts{i} = cv.Facemark.loadFacePoints(ptsFiles{i}); end
Loading data...
Init
create instance of the face landmark detection class, and set the face detector function
obj = cv.FacemarkKazemi('ConfigFile',configFile);
obj.setFaceDetector(faceDetectFcn);Train
perform training
disp('Training...') tic success = obj.training(imgs, pts, configFile, scale, 'ModelFilename',modelFile); toc if success disp('Training successful') else disp('Training failed') end
Training... Elapsed time is 78.617735 seconds. Training successful
In the above call, scale is passed to scale all images and their corresponding landmarks, as it takes greater time to process large images. After scaling data it calculates mean shape of the data which is used as initial shape while training. It trains the model and stores the trained model file with the specified filename. As the training starts, you will see something like this:

The error rate on trained images depends on the number of images used for training:
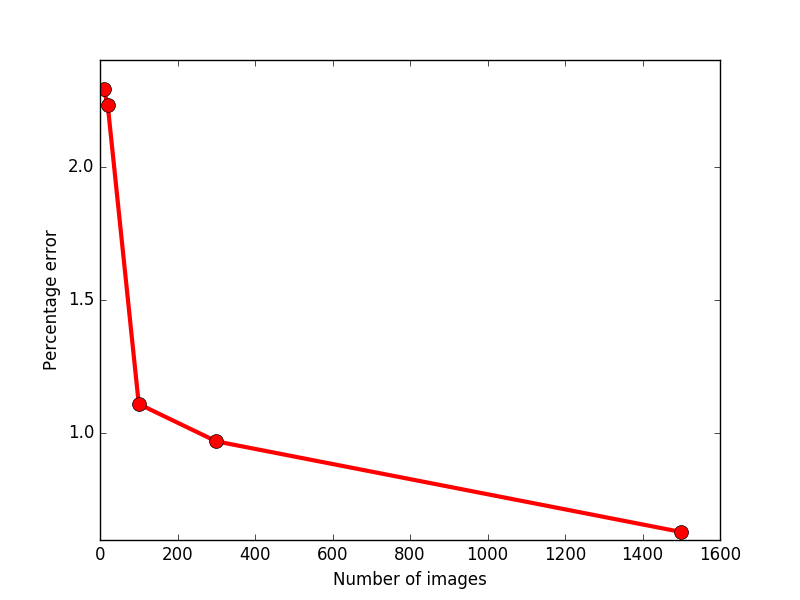
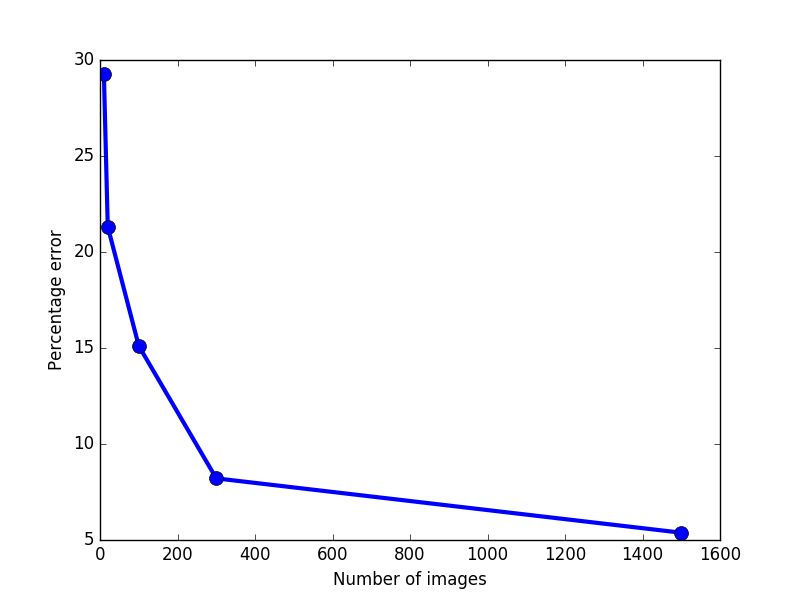
The error rate on test images depends on the number of images used for training:
Helper functions
function download_classifier_xml(fname) if exist(fname, 'file') ~= 2 % attempt to download trained Haar/LBP/HOG classifier from Github url = 'https://cdn.rawgit.com/opencv/opencv/3.4.0/data/'; [~, f, ext] = fileparts(fname); if strncmpi(f, 'haarcascade_', length('haarcascade_')) url = [url, 'haarcascades/']; elseif strncmpi(f, 'lbpcascade_', length('lbpcascade_')) url = [url, 'lbpcascades/']; elseif strncmpi(f, 'hogcascade_', length('hogcascade_')) url = [url, 'hogcascades/']; else error('File not found'); end urlwrite([url f ext], fname); end end % The facemark API provides the functionality to the user to use their own % face detector. The code below implements a sample face detector. This % function must be saved in its own M-function to be used by the facemark API. function faces = myFaceDetector(img) persistent obj if isempty(obj) obj = cv.CascadeClassifier(); obj.load(xmlFace); end if size(img,3) > 1 gray = cv.cvtColor(img, 'RGB2GRAY'); else gray = img; end gray = cv.equalizeHist(gray); faces = obj.detect(gray, 'ScaleFactor',1.4, 'MinNeighbors',2, ... 'ScaleImage',true, 'MinSize',[30 30]); end